

METR’s bombshell paper about AI acceleration
About the author: Peter Wildeford is a top forecaster, ranked top 1% every year since 2022. Here, he shares analysis that informs his forecasts.
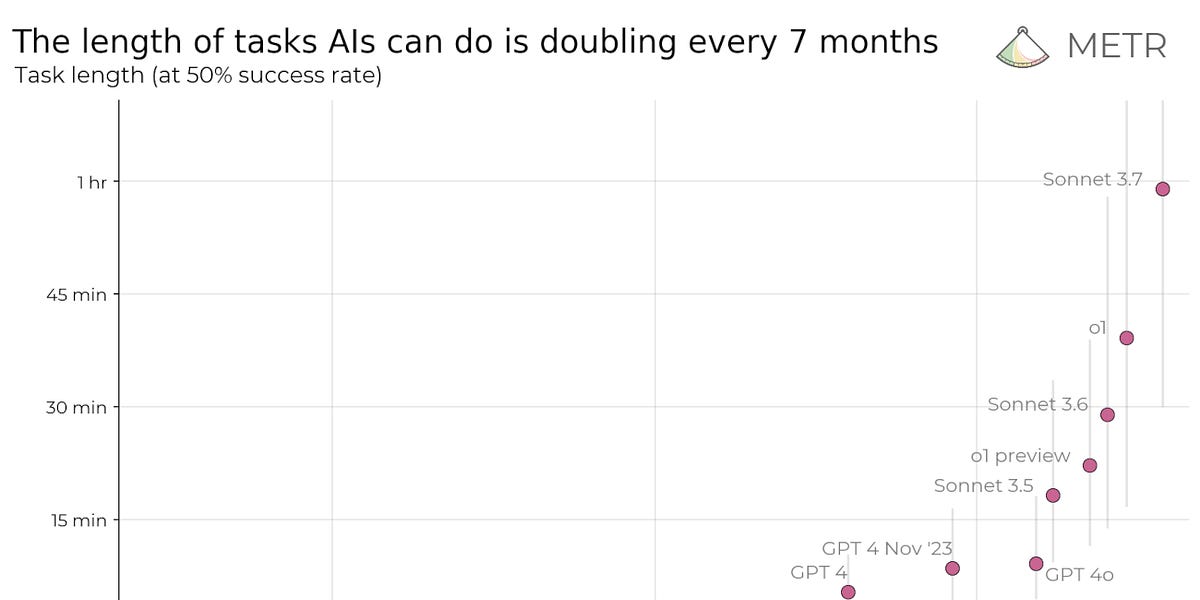
About a month ago, METR, an AI evaluations organization, published a bombshell graph and paper that says that AI is accelerating quickly. With OpenAI’s recent launch of o3 and o4-mini, we can see if these predictions hold up.
The simple version of this chart is easy to explain. Claude 3.7 could complete tasks at the end of February 2025 that would take a professional software engineer about one hour. If this trend holds up, then seven months later at the end of September 2025 we should have AI models that can do tasks that take a human two hours. And in April 2026, four-hour tasks.
You can see where this goes…
-
day-long tasks (8hrs) by November 2026
-
week-long tasks (40hrs) by March 2028
-
month-long tasks (167hrs) by June 2029
-
year-long tasks (2000hrs) by June 2031
o3 gives us a chance to test these projections. We can see this curve is still on trend, if not going faster than expected:

AI tasks are growing on an exponential — like how early COVID cases seemed like nothing, but then quickly got out of control.
Does this mean that AI will be able to replace basically all human labor by the end of 2031? Can we trust this analysis?
Let’s dig in.
Here’s the methodology:
-
Create a diverse suite of software engineering tasks to test AIs and humans on.
-
Hire a bunch of human software engineers as contractors, see how long it takes on average for them to complete each task.
-
Run a bunch of AIs on these tasks, see if they complete the tasks or not.
-
For each AI model (e.g., o3), see what tasks it succeeds on and what task it fails on. Sort these tasks by the amount of time it takes humans to complete them. Then plot this as a graph.
-
Find the value where the success rate equals 50%. This is the “task length at 50% reliability” for that AI.

-
Once we have this estimate for each model, we can plot it on a graph
-
Then we can try to fit a trend line

-
We then try to figure out what level of “task length at 50% reliability” it takes to be equivalent to AGI, see when the trendline thinks we will hit that mark, and declare that to be the date of AGI.
Of course, this is a bit silly. Making graphs is the easy part, interpreting them is harder. Let’s try to bring this analysis down to Earth and refine it some more.
Let’s take a deeper look at what tasks METR is asking the models to do. The paper gives these examples:

p13-14 of the HCAST paper and p19 of the “Long Tasks” paper do a good job of covering some of the issues with generalizing these tasks:
-
These are all software engineering tasks: We don’t get to see tasks across other domains relevant to remote work, where AI might struggle more.
-
All tasks are clearly defined and automatically scored: Each task tells you exactly what to do and exactly how you succeed. The real world is rarely like this. This could be an important way models get stuck that is not covered in METR’s tasks.
-
Everything is solitary, static, and contained: The tasks are designed to be done autonomously in a single computer session in an unchanging and uncompetitive environment. Agents don’t need to coordinate or gather information across a wide variety of sources. This is very unlike the real world.
-
There’s minimal cost for waste or failure: Exceeding the cost of human performance, using compute inefficiently, overusing limited resources, or making multiple mistakes are typically not punished in the task set, with a few exceptions. This may also be unlike the real world.
-
Learning effects are ignored: METR found that the dedicated maintainers of a particular GitHub repository were 5-18x faster at completing tasks related to that repository than contractors that were skilled software engineers but otherwise had minimal prior experience with the repository. These contractors are the types of baseliners used for estimating the length of the tasks in METR’s task suite, which means learning effects are ignored. Humans are likely hired in part because of their ability to master very niche tasks by accumulating learning over time – current AI models do not experience these training effects.
-
Reliability matters – METR is judging AIs based on the length of tasks they can do at 50% reliability. But in the real world you may want higher than 50% reliability at a particular use case, depending on the task. When looking at where AIs can do tasks with 80% reliability, you get the same doubling time but starting from a lower base of only 15 minutes.
The bottom line is that work on AGI and automating the economy relies not on replacing just human software engineers, but replacing all work. METR’s task list is a significant advance in being able to track AI progress on complex tasks, but it is definitely not a benchmark of all human labor.
This is important because I would guess that software engineering skills overestimate total progress on AGI because software engineering skills are easier to train than other skills. This is because they can be easily verified through automated testing so models can iterate quite quickly. This is very different from the real world, where tasks are messy and involve low feedback — areas that AI struggles on. When you look at all tasks relevant to AGI, you may end up with very different reliability curves and doubling rates, which is a real challenge for this analysis.
In fact, the range of what AI can do is fairly different from humans and cannot be easily compared. Recall that AI can become fluent in over 100 languages simultaneously in just three months and can read thousands of words per minute. But at the same time, AIs still struggle on simple tasks that humans can do very easily. While METR discusses AI being able to do >1hr software tasks, there are many simple tasks that many humans can do in less than a minute that AIs cannot do.
Consider o3 spending 13 minutes using a wide variety of advanced image processing tools to analyze this simple doodle trying to match arrows to stick figures and still failing – a task that a six-year-old child could do in a matter of seconds:
Similarly, AI still fails to do basic computer use tasks that take humans less than a minute – such tasks would be critical for achieving an AGI that aims to do remote work. And there are many other embarrassing failures, such as making simple mistakes at tic-tac-toe, not being able to count fingers, getting confused about simple questions, and thinking some of the time that 9.11-9.8 = 0.31.
Thus it matters where you index to. When looking at AI’s strengths, it’s easy to make a mistaken extrapolation that makes AI seem impressive. Consider that specialist AIs like Stockfish / AlphaZero can identify chess moves that take humans many years to equivalently analyze. If you take this domain and extrapolate it, it predicts that AI can operate at the scale of decades, well beyond AGI, which is obviously not true. This is because chess is not representative of AGI tasks.
But when indexing to AI’s weaknesses, it’s easy to think that AGI will never be achieved. The true answer lies somewhere in between, where we have to be more careful in terms of figuring out what the collective range of tasks automating all human labor will require and figuring out what task length AI has among that larger, more general, more messy group of tasks.
Another core issue with the methodology of projecting out the exponential is we don’t know if it will keep going that way. Progress in the METR paper is presented as an inevitable consequence of the unfolding time, but actual AI progress comes out of increased capital spending, increased compute efficiency, algorithm development, etc. These are all happening very fast right now, but they may soon instead slow down. It’s going to get harder and harder to 10x the compute of models and 10x the amount of money spent on them. Data availability might become an issue.
And it’s also still unclear how much reasoning will scale, or if new techniques will arise that improve scaling. So much of AI is new and still under development. We’re not in a paradigm of iterating over different amounts of training compute, but instead we’re dealing with a lot of different variables changing at once, and the chance to introduce new variables. This makes extrapolations even more confusing.
And longer task times might create more than linear levels of increased complexity. The doubling rate could become longer over time now that we’ve done all the “low hanging fruit”. These are all challenges to the unfolding of the exponential, and it makes it natural to think scaling will slow down soon.
Ultimately the problem with projecting a line going up is that sometimes the line stops going up. For example, “baby scaling” goes fast in the first few years, but then hits a slow point:
However, for AI we really don’t know where this slow point is or if the lines will ever slow. This is still very uncertain. Calling the top on the AI scaling curves so far has been notoriously difficult. Many scaling doubters have been proven wrong over the past few years.
On the other hand, we should keep in mind that METR might be underestimating AI progress and that actual trends could be faster than the median line METR presents.
Most notably, p37 of the “Long Tasks” paper shows that if you look at the trend solely over 2024-2025 (GPT4o launch to Claude 3.7 Sonnet launch), then the doubling time is about twice as fast (118 days instead of 212)! This could get to one-month tasks by September 2027!
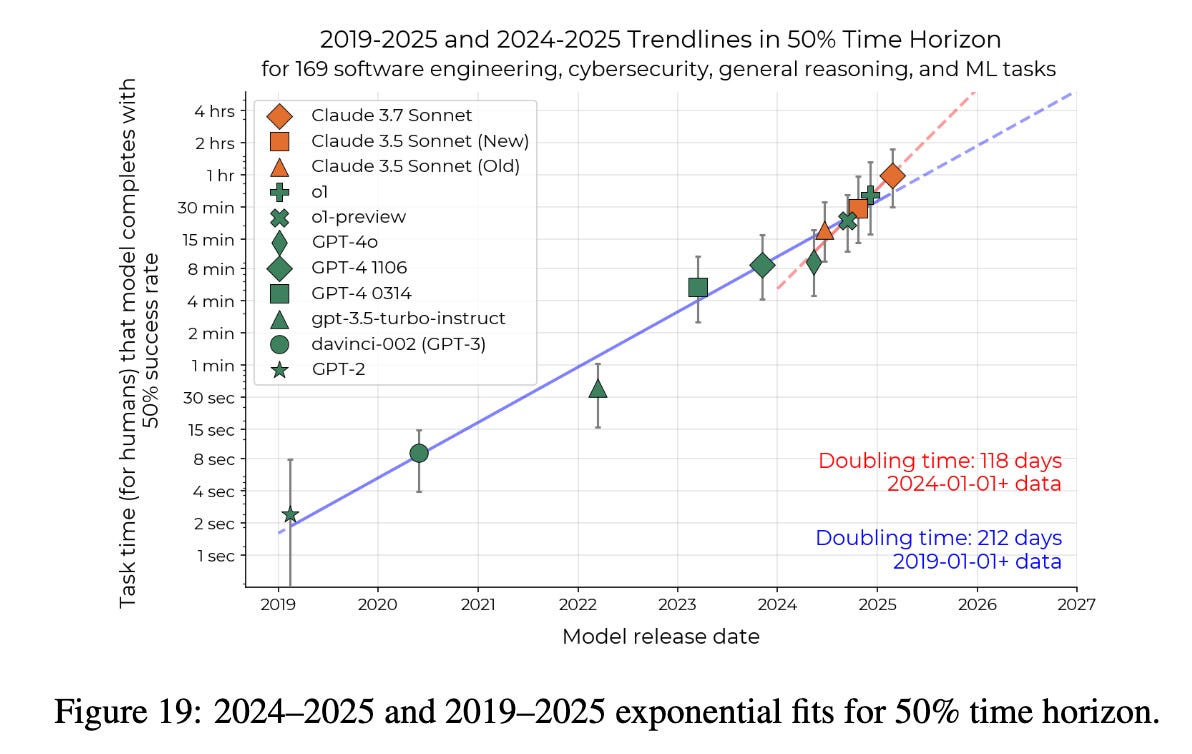
This is further confirmed by o3 and o4-mini, which show a doubling occurred in 63 days rather than the typical 212.
And there are other points that suggest a speed-up is possible:
-
Internal models might be ahead of the public state of the art. When Claude 3.7 was released, it is plausible that Anthropic might have had a better model internally that could perform even better on the tasks. This means that the true best capabilities as of today might be slightly better, as we only see models when they are released. Similarly, o3 may have had >1hr performance back in 2024 December when it was first announced or even earlier than that as it was being trained, but it wasn’t released publicly until 2025 April.
-
Agency training: The type of “agency” training needed for models to excel at software engineering is just starting. This is the exact type of model training that would be necessary to help models excel at many-step problems and solve longer tasks. There could still be room for much faster growth.
-
Inference-time compute: Reasoning skills likely improve with even more compute spent thinking about the problem. METR notes that “more than 80% of successful runs cost less than 10% of what it would cost for a human to perform the same task” (p22 of the “Long Tasks” paper). This suggests that there’s room to more efficiently allocate spending to help models solve tasks while still being competitive with human rates.
-
Feedback loops: A core way AI progress is made is through researcher experimentation and iteration, which can potentially be sped up by AI tools. If future AI could automate and greatly expand the amount of R&D that can be done, that could compound, improving models more quickly. This potentially motivates a superexponential curve of AI progress, where the doubling rate itself increases faster over time.
-
Improving scaffolding could matter: Raw AI models like GPT4 out of the box don’t perform well on these tasks. Instead, additional programming is done to build systems and tools around the AI that allow the AI to take multiple steps, browse the internet, execute code autonomously, learn from bugs and errors, and iterate. This is referred to as ‘scaffolding’. Improvements in scaffolding can make the exact same AI more capable by helping it better harness its strengths and avoid weaknesses. METR has worked hard to improve their scaffolding, but future improvements are likely still possible. This is an underrated source of AI progress.
If we’re trying to automate the economy, you’d want to know what level of task length individual jobs require. Is there a such thing as a year-long task? Perhaps just limited to people writing novels or some other long-running multifaceted, deeply integrated piece of work. Instead, careers would be composed of many hour-long tasks, day-long tasks, and maybe even the occasional month-long task. You keep iterating over these tasks and composing them into a longer piece of work.
For example, while I’ve been writing this Substack for a few months, it is composed of individual blog posts that each take 3-20 hours to write. So if AI could automate all aspects of a 20-hour writing task as good as me, the AI could potentially have a compelling Substack too by just chaining together a bunch of 20-hour tasks producing individual posts.
Following this logic, METR thinks that an AI capable of one-month work would be an AGI (see p18-19), given that a lot of economically valuable work, including large software applications, can be done in one month or less. Additionally, one month is about the length of a typical company onboarding process, suggesting that an AI with a one-month task length could acquire context like a human employee.
But is that true? For example, how much does my prior experience writing Substacks help me write the next one more effectively, and how does that count towards the task length? And what about how much I draw on my depth of expertise across forecasting, AI, and policy, which comes from years of experience? Does that make each Substack post a year-long task or more? I have no idea. Ajeya Cotra on Twitter notes:
I’m pretty sure I’d be much worse at my job if my memory were wiped every hour, or even every day. I have no idea how I’d write a todo list that breaks down my goals neatly enough to let the Memento version of me do what I do.
Together, this makes it a fairly fuzzy boundary for when METR projects we reach AGI. I’m not sure the boundary could be that clear cut and there is significant uncertainty here.
We can actually attempt to use the METR paper to try to derive AGI timelines using the following equation:
days until AGI = log2({AGI task length} / {Starting task length}) * {doubling time}
Here’s an example of what this looks like if you plug in my preferred assumptions (or feel free to make your own and do the math):
If you make all these assumptions and do the math, AGI is achieved 1778 days after o3 launch, or 2030 February 28.
~
We can extend this into a formal model with uncertainty across what level of task mastery, reliability, and task length is needed to achieve AGI, as well as different ways of calculating the average doubling time will be over the course of now to AGI.
Doing so produces the following …this plots 200 individual model runs, with AGI arising at the red “X”s.
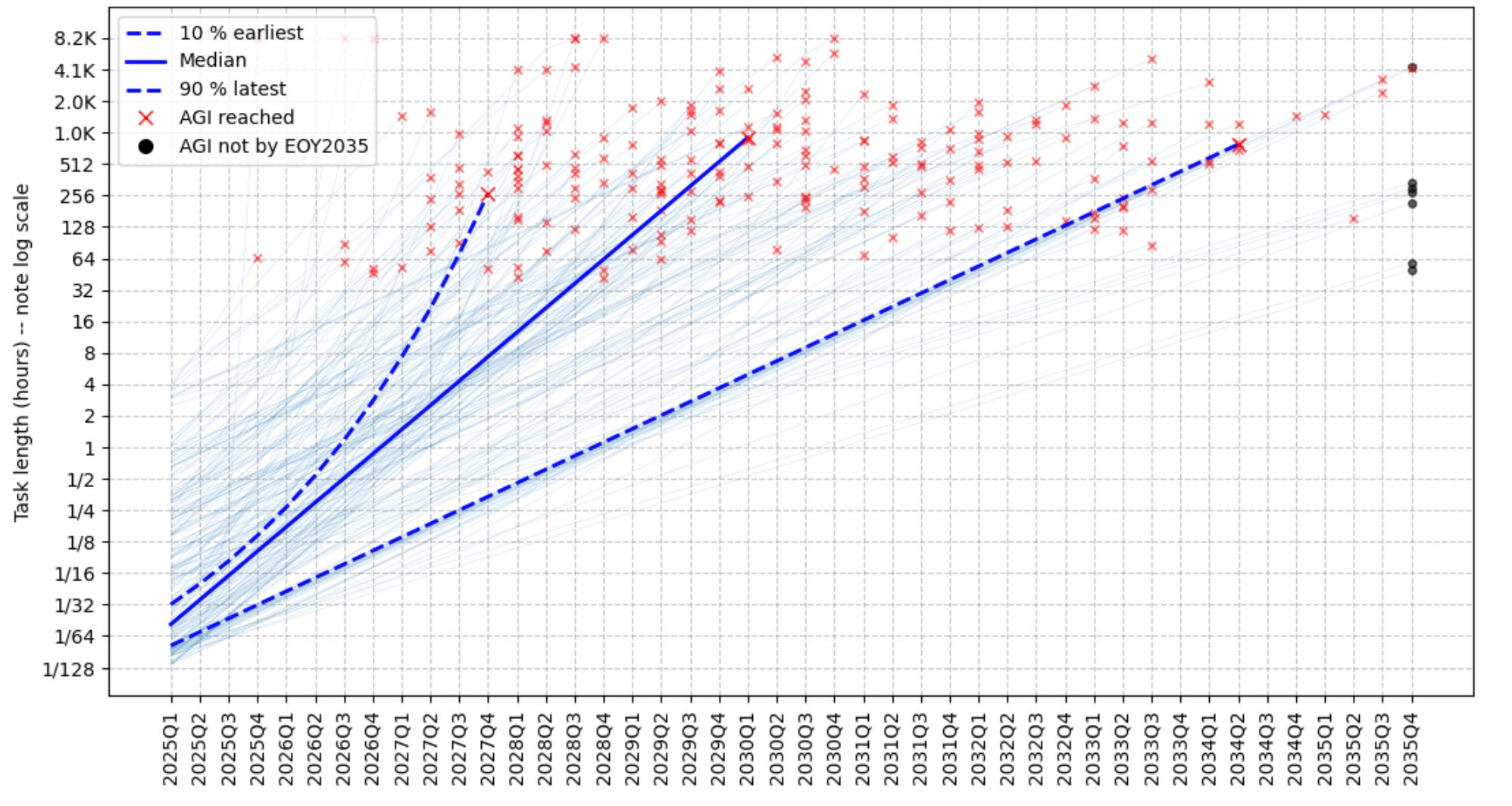
This model suggests a median arrival date of 2030Q1 for AGI, with a 10% chance of achieving AGI before the end of 2027 and a 90% chance by the end of 2034Q2. (Variable definitions + full code available for nerds in this footnote:)
Additionally, according to this model there is a ~0.1% chance of achieving AGI this year, a ~2% chance of AGI by the end of 2026, and a ~7% chance by the end of 2027.
[NOTE 2025 JUN 21: The numbers above no longer represent my best guess, as we’ve learned more since this post was written. Some changes are instead explained here. This will be written in a Substack post in a future date that will supersede this post.]
But four additional notes on this model:
-
This is not an ‘all things considered’ model! Before you screenshot this and say “Peter thinks AGI is coming in 2029!”, keep in mind that this model is just taking into account the results from the METR paper with some uncertainty provided, but still contains significant additional uncertainty around methodology. Other parameters around capital slowdown and AI progress diminishing returns could be modeled more explicitly. At the same time, possible new innovations that may speed up AI progress are not taken into account either.
-
This assumes “business as usual”. This does not account for possible changes in the general dynamics (strong economy, lack of major war, lack of regulations) from which AI has developed over the past five years. Exogenous shocks could slow down AI development.
-
“Achieving” AGI does not mean that AGI will be widespread. There will likely still be delays in commercializing and widely rolling out the technology.
-
In practice, the curves might be jagged rather than nice curves. That is, we might see a bunch of progress in task length before hitting diminishing returns or hitting a wall. Additionally, advancements in scaffolding or algorithms could produce a sudden burst in progress.
Are we close to or far from AGI? The METR paper is indeed a great contribution towards estimating this. While the tasks collected are still far from an exhaustive collection of all tasks that would be relevant to AGI, they are still the most varied and compelling collection and systematic analysis of tasks we have to date.
And what we’re seeing is weird. Models that can debug complex PyTorch libraries better than most professional software engineers yet still struggle with very simple computer use tasks or the ability to follow arrows in a simple drawing remind us that AI capabilities remain incredibly uneven and difficult to generalize. The gap between performing well on clean, well-defined software tasks versus navigating the messy uncertainty of real-world problems remains significant. This thus allows for significant uncertainty about when AGI will be achieved.
Nevertheless, the trends appear robust. With each new model release — Claude 3.7, o3, o4-mini — we’ve seen capabilities align with or exceed even the optimistic projections. The extraordinary pace of progress suggests we should take seriously the possibility that AGI could arrive much sooner than conventional wisdom suggests, while maintaining appropriate skepticism about extrapolating current trends too confidently.
And the best part is that this model can be used as an early warning system. We can continue to observe AI progress over time and see what trend it is following and use that to narrow the model and build more confidence in our projections. This could help us see massive AI progress and give us more time to prepare.